By Gabriel, 31 Aug 2023 , updated 02 Sep 2023
Why and How to run your own Large language model on your traditional cloud provider like AWS.
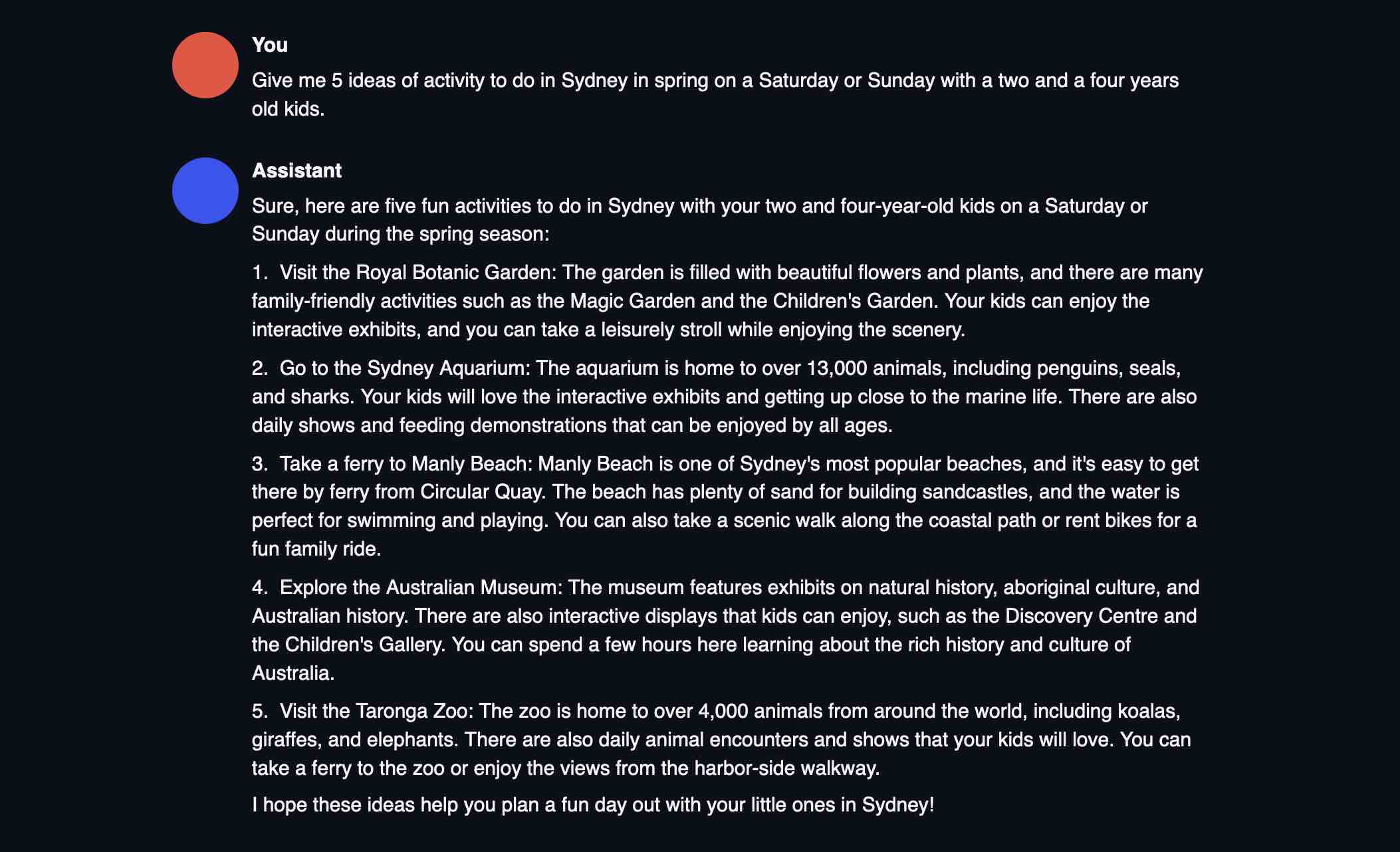
Chat with oobabooga text-generation-webui using Meta’s Llama 2 13B-chat model
Large Language Model (LLM) tools like chatGPT and Github Copilot can increase productivity for developers. At the same time they are third-party hosted and this has raised some concerns about the usage of our sensitive data in my company if we were to generalise the usage of those tools. In Software development one important concern is: will the details of our implementation (and potential vulnerabilities) leak into the response to other users of those tools. (ChatGPT and Github Copilot state that they may include user submitted data to improve the product)
In the other hand some ChatGPT~equivalent LLM have been released, a well known one is LLaMA by Facebook. And there is countless examples on Internet of people running them efficiently on their personal computer, that is far from the expensive and complex GPU-powered servers on Microsoft Azure used to run ChatGPT.
Pausing here for a second to insist on that important point, well known from subject-matter experts but maybe not from other people even IT worker: it IS possible to run locally, that is in complete isolation, on a big but affordable machine a LLM almost as-good-as the current ChatGPT. One would just have to download for free the “weights” of a model and the software to run it (the inference engine), give it a “prompt” and execute it.
Most of the examples or running your own LLM I have seen out were from developer running it on their own (beefy) machine. Here I want to describe how to run it on some ordinary cloud provider AWS (but can be a competitor) and how to add a friendly web interface on it so it can be shared with a private group of users (company, association, school).
There are a lot of openly available models out there now, keeping up with all of them is now impossible. I am more familiarised myself with the LLaMA-derivated models:
The good things is that once you have that architecture to run your own LLM you can switch from one to another easily and pick the one that offer the best compromise for you. More details below on you can make that work here.
Traditionally the inference engine required for those LLM run on GPU-machine, not CPU-machine, ie not our most commonly available computer at home or even in the cloud to run websites. Loads of massive matrix multiplications are executed in the neural network that constitute the engine. GPU have many more (smaller) cores than CPU hence perform better. A breakthrough came from the community of open source in March when Georgi Gerganov released llama.cpp: it is a port of a GPU-inference engine to CPU architecture with quantization technique (GGML) along the way to reduce the amount of computation required and make it practical. His attempt has been since further improved by others. It has open-up the space for more applications of LLM, and it is the approach I am describing in that post.
Based on other people experiences, willing to run a 13B model practically and mindful of the renting cost! I have choose a
m5.2xlarge EC2 instance - 8 cores, 32GB RAM - Spot price ~0.16 USD / hour
It is possible as well to run your own LLM staying on GPU-machine at AWS (SageMaker) but that is not the goal here.
Now let’s get started!
Prerequisites: Have an AWS account and be familiarised with AWS console and the process of EC2 instances creation (including attaching related resources like EBS storage), using ssh
lsblksudo file -s /dev/nvme1n1sudo mkfs -t ext4 /dev/nvme1n1sudo mkdir /datasudo mount /dev/nvme1n1 /data/cd /datasudo yum updatesudo yum install gitsudo yum groupinstall "Development Tools"cd /datamkdir models ; cd modelswget -S https://huggingface.co/TheBloke/LLaMa-13B-GGML/resolve/main/llama-13b.ggmlv3.q4_K_M.binwget -S https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GGML/resolve/main/vicuna-13b-v1.3.0.ggmlv3.q4_K_M.binwget -S https://huggingface.co/TheBloke/LLaMa-7B-GGML/resolve/main/llama-7b.ggmlv3.q4_K_M.binwget -S https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/llama-2-13b-chat.ggmlv3.q4_K_M.bin <- new oneddwget https://github.com/oobabooga/text-generation-webui/releases/download/installers/oobabooga_linux.zipunzipcd oobabooga_linuxchmod u+x *.shstart_linux.sh (first is long because installation of dependencies)cd /data/oobabooga_linux/export OOBABOOGA_FLAGS="--listen --chat --model-dir /data/models --model vicuna-13b-v1.3.0.ggmlv3.q4_K_M.bin --gradio-auth myusername:mypassword --threads 8". Notes about those values:
./start_linux.shThen browse the URL: http://[YOUR-INSTANCE-IP]:7860 !
Prompt: “Implement a regular expression in Python to validate an email address.”
The simplest regex is this one: [a-zA-Z0-9]+@[a-z]{2,4}
We can write a simple function that does the validation of emails for us and we will use it later on when we create our program to send/receive emails. We can do something like this (this is written in Python):
def validateEmail(emailAddress: str) -> bool:
emailPattern = re.compile("[a-zA-Z0-9]+@[a-z]{2,4}")
matched = emailPattern.match(emailAddress)
if not matched: return False # if the pattern did not match
return True # everything is fine!
The function will return a Boolean value depending on whether it matches with our pattern or not. If we do this validation before sending an email, we can be sure that there won’t be any errors in your emails and you don't have to [truncated]
import re
def validate_email(email):
# Regular expression pattern for validating email addresses
regex = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
# Check if the input is a string and not empty
if type(email) != str or email == "":
return False
# Use re.match() to match the pattern in the input string
match = re.match(regex, email)
# Return True if the email address is valid (i.e., the match object is not None)
return match is not None
You can easily change the model if a new one is getting very popular or if you find one that meet well your requirements. The web admin allow you to change a lot of settings that will modify the way to run the model and will result in different response for the same prompt (longer response, more precise, longer to produce…). I’m not familiar with those.
After I completed the steps above to reach this prototype, I applied some time and effort to productionise it, making it easier for me to repeat the process. This post is already a bit long but I can share more later or upon request. Things like:
aws ec2 run-instances because command line is faster than multiple click in the Console Admin once one know what to do.Running a model is not very difficult nowadays thanks to the work and open source release of many contributors. Models do improve continuously (see difference above between the “deconstructed” response from llama-13b and the real code produced by vicuna-13b. I have experienced myself several of those tools as an assistant while coding for several months now and it really increase the productivity. Now it is not clear to me yet what other every-day applications one can make of it (there is a lot of hype as well in the space) But I’m excited about the future usages that people will find.