By Gabriel, 28 Feb 2026 , updated 09 Mar 2026
This post is about a prompt development experiment using several Github-copilot-provided models to develop python scripts to download and upload to S3 some images.
The main idea of this experiment is to compare several models at generating code purely from instructions without any manual code change of a real-world task. I have qualified it as iterative because, as a normal real problem, the requirements were not fully defined at the beginning.
I have used the prompt driven development (PDD) naming.
I have not used the term “vibe coding” because I felt that I wanted to be quiet specific in the prompts I used (instructing library to used, log messages to output, steps to follow, …). But maybe this is still a form of it!
I have not used Spec-Driven development (SDD). SDD seems stricter, it seems that particular care is applied to structuring and storing the specifications with the code.
Anyway, all of them being current AI coding buzzwords, their definitions are still in flux and already semantically diffused. But at the time and with my current knowledge of the AI coding jargon it seems a good description of this experiment.
The AI coding assistant is NOT used in agentic loop. Only one LLM call is made at each round.
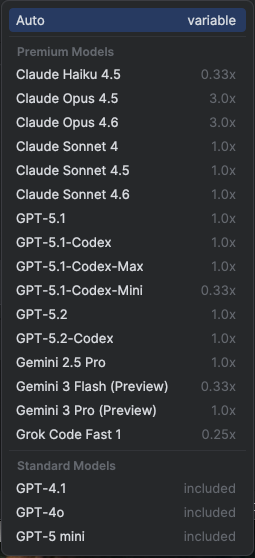
At the time of writing this post, the list of models provided by GitHub Copilot in my situation (Business plan - using GitHub Copilot plugin for JetBrains IDE) is the following:
16 Premium Models
Premium models consume “Request” quota. The multiplier (e.g., 0.33x) indicates how many credits are deducted per request compared to a standard baseline.
Each copilot features (Copilot Chat, Copilot CLI, …) except for Spark (…) uses one premium request per user prompt, multiplied by the model’s rate. See Requests in GitHub Copilot.
The Business Plan, 19 USD per user / month, includes 300 premium requests per user / month. See GitHub Copilot plans & pricing
3 Standard Models
Standard models are included in the base subscription and do not count against my premium request limit
On a side note, considering the fast evolution of the models it is interesting to step back and acknowledge today (Feb-2026):
Reflect what it was in the past:
And come back to that in 6 months, 1 year or a little bit more to see how it will evolve. Spoiler: the most valued models of today could be the basic models of tomorrow or even disappear from the list of models available!
List of models reviewed:
The topic of the task is purposefully simple, way simpler than the tasks that can be handled today by AI coding assistants, even using a simple model. It is to allow the reviewer (me!) to perform a quicker and thorougher code reviews. I believe that a lot of the learnings and insights from this experiment can be extrapolated to more complex tasks. Actually as I went through the experiment, reading about a model and then using it here, I changed a bit my mind. I realised that this too simple task will fail to capture all the benefits of the most advanced models published in those last 3 months (GPT-5.2 and Claude 4.6). But let’s pursue this experiment as it is, draw some insights and then maybe do another one later, more complex.
See the git repository to check details of the experiment conditions, all the prompt rounds and the generated (and tested) code for each reviewed model: https://github.com/danrit/exp-gh-copilot-compare
Here are a list of findings I have collected, no particular order. It may appear harsh toward the output of the llm sometimes. but I think the comments I’ve raised would have been raise to me as a developer or by me a stakeholder if I had produced that code
upload.py the model reuse the same pattern of logging as done previously in download.py. This is good as it simplify the prompt on the next step (5)With the technique used (multiple rounds until success, with manual testing) and the simplicity of the task all models were able to implement the requirements. But with very different line-to-line implementation. In fact it is challenging to compare 2 implementations. So how can we compare the “quality” of the output?!
In the table below I have tried to report on some measurable differences.
download.py:
| branch_name | total_lines | code_lines | comment_lines | function_definitions | max_nesting_level |
|---|---|---|---|---|---|
| gpt-5-mini | 125 | 85 | 40 | 2 | 8 |
| gpt-5-2 | 150 | 122 | 28 | 6 | 4 |
| claude-sonnet-4-6 | 116 | 84 | 32 | 4 | 3 |
| claude-opus-4-6 | 82 | 65 | 17 | 1 | 3 |
upload.py:
| branch_name | total_lines | code_lines | comment_lines | function_definitions | max_nesting_level |
|---|---|---|---|---|---|
| gpt-5-mini | 256 | 190 | 66 | 7 | 10 |
| gpt-5-2 | 230 | 196 | 34 | 8 | 4 |
| claude-sonnet-4-6 | 193 | 149 | 44 | 6 | 7 |
| claude-opus-4-6 | 165 | 144 | 21 | 2 | 6 |
More advanced models tend to produce smaller code (less line of codes) and simpler (less nesting level) code.
Here is a list if ideas I would explore next if I were to pursue this experiment:
First, those models are globally good at implementing the requirements, with little trial and error (ie here with just a few extra rounds)
When I went to compare the generated code of two models I found a lot of little difference (spacing, quotes, choice of comment, preferred util function…) that make the code hard to compare. Make me realise with AI generate code, we shall still apply (and probably even more) some code style guide, formatting rules… It is important to make the code (as much as it is possible) more stable!
The pattern now with developer now using AI agent, you write “plain english” specifications and then review the generated code. Now, if you are aiming for a productivity gain (which is the main selling point of those tools) you have to relinquish some control over the generated code. You cannot possibly spend as much time reviewing the implementation (reading, thinking, imaging scenarios) as you would have spent writing it yourself. The same way you would have to relinquish some control if you were to delegate the task to another developer. (But in this case it is not someone that you can have a conversation with and ask for clarification, so it is a bit different). There are ways around that, to make it work I suppose: more high level review, focus on the important implementation choice, develop good understanding of the models, use good test coverage, … but that is another subject.
I do realise that advanced and proprietary models inference pricing is significantly higher than open weight models (whose pricing, because of the competition, is simply related to inference cost, hence lower). I feel that sometime it worth it sometines it doesn’t:
I started that experiment with a very begin-2025-view of the AI coding assistant capabilities. What I mean by that is that while I knew that it could already provide productivity gain, I was sceptical about the quality of the code generated and the complexity of the task it can handle. But various readings during that time make me realise that recent models (gpt 5.2, Claude Opus 4.5 and above) have improved a lot. We have not figure out how to use them in the best way on mission critical software yet. However I do believe that soon developers will not be required to hand write code line by line. For that to happen we do need to figure out ways to architect, structure, channel and validate the generated code in a codebase in the long term and still deliver safely mission-critical software.